Scrape Yelp Reviews with Python: Full Extraction Guide in 2025

Trying to scrape Yelp review data reliably but can’t get past the first few steps? Yelp holds user-generated business reviews that are packed with insights.
Naturally, many seek to access this data through the platform. But when done programmatically, Yelp pushes back to prevent misuse through several layers of defense. That doesn’t mean scraping Yelp reviews is off-limits entirely.
This guide helps you get started with Yelp reviews. You’ll learn how to build a review scraper that collects clean, structured data. We’ve also included responsible scraping practices and tips to reduce the chances of getting blocked.
What To Know Before You Start Scraping Reviews?
Before setting up the Yelp review scraper, it’s important to cover these few basics. This helps you avoid common mistakes and understand how Yelp’s review system works.
- No Login Required: Yelp allows a few listings to be accessed publicly. You don’t need to log in or solve CAPTCHAs to access most business pages.
- Reviews Load via GraphQL: The reviews aren’t listed in the page HTML. Yelp uses a GraphQL API to load reviews dynamically after the page loads.
- Business IDs are hidden: The business ID “yelp-biz-id” is not part of the URL. It's embedded inside a meta tag in the HTML source. Hence, you need to extract to make review API requests.
- Pagination Uses Offset Tokens: Yelp doesn’t load all reviews at once. To go beyond the first page, you must calculate and send a base64-encoded offset value with each GraphQL request.
- Yelp GraphQL isn’t Official: GraphQL is a query language for APIs, and Yelp doesn’t offer any Public API. The scraper uses an internal endpoint meant for their own site, so it may break if Yelp updates it.
- Aggressive Scraping Can Get Blocked: Although the reviews are public, Yelp sets rate limits. Hence, be aware before proceeding with scraping multiple reviews at once.
How To Set Up a Yelp Review Scraper?
Now that you know the basics, you're all set to create a simple Yelp review scraper using Python. Keep in mind that this scraper focuses specifically on extracting customer reviews and associated data only. We don’t collect business listings, photos, or other profile metadata.
To make it easier for you, we have divided the code into multiple steps. Each step builds the scraper while explaining what’s happening behind the scenes.
Prerequisites
Start by installing Python and a Python-friendly IDE like PyCharm to create a new project. Once done, you’ll also need to install a few Python packages. To do this, open the terminal and enter the following command.
Why do we need these packages? They are necessary for the code to function properly. Here’s a quick breakdown.
- httpx: A fast and modern HTTP client for making requests
- parsel: Used to parse HTML and extract the business ID from the Yelp page
- jmespath: Helps extract nested fields from the JSON response (especially useful with GraphQL)
Step 1: Set the Business URL and Output Settings
We begin by importing the required libraries. These play a key role in the HTTP requests (httpx), HTML parsing (parsel), data extraction from JSON (jmespath, json, base64), and saving the scraped reviews into a structured CSV file (csv).
Next, we declare a few variables to control how the scraper behaves. For demonstration, we’re targeting a single restaurant. Copy the URL of the restaurant from Yelp and assign it to BUSINESS_URL. We’ll collect up to 30 reviews, with each GraphQL request returning 10 at a time. The final output will be saved to a file named reviews.csv
Finally, we define HEADERS to mimic a real browser. This helps avoid being blocked by Yelp’s server. The User-Agent string tells Yelp that the request is coming from a common desktop browser, and the Origin header sets the expected source domain.
With these in place, we’re now ready to locate the hidden business ID required for scraping reviews.
Step 2: Extract the Business ID from the Yelp Page
As said before, Yelp doesn’t include the business ID in the URL, but it does place it in the page’s HTML source. Here, we are defining a function that sends a GET request to the business page. It parses the returned HTML and looks for a <meta> tag named yelp-biz-id. It’s the key to our treasure hunt.
If the ID isn’t found, the function raises an error to stop execution early. This prevents the scraper from running with invalid or missing data. We also extract the business name from the <h1> tag to label it in the output later.
Step 3: Prepare the GraphQL Review Query
Before we fetch any reviews, let’s clear the common confusion as to why GraphQL is preferred instead of BeautifulSoup. The reason for this is that BeautifulSoup is great for parsing HTML, but Yelp loads its reviews dynamically.
By using GraphQL directly, we bypass the need to simulate browser behavior and get cleaner, structured data much faster.
The payload is the actual GraphQL query sent to Yelp. It tells the server which business we're targeting (encBizId). Plus, it also includes how many reviews to return, what languages to include, and how to sort them.
Next, we copy the global headers and add a few required fields specific to this request. These include the Referer (which must match the Yelp business page), a JSON content type, and an internal field used by Yelp's frontend framework.
At last, we send a POST request to the GraphQL batch endpoint with the payload. If the request fails, we raise an error. Otherwise, we return the first response object from the list, which contains the full review data for that batch.
Step 4: Handle Review Pagination Using Offset Encoding
It is unclear how many reviews a business can have. Yelp doesn’t make the mistake of loading them all at once. Instead, it displays only 10 reviews per page through pagination.
Since we’re trying to scrape 30 reviews from the business, we need to go beyond Page 1. But because we’re using Yelp’s GraphQL API, we can’t just pass something like ?page=2. So, we use an encoded string called after, which tells the server how far into the review list we are.
So, how to get the right after value? We define a small utility function that takes a numeric offset and wraps it into a JSON structure that Yelp expects. Next, it base64-encodes that JSON string so we can use it in our GraphQL payload.
Step 5: Parse and Clean the Review Data
With pagination handled, we can now start parsing the actual review content from the server’s response. The response from GraphQL is a nested JSON structure. But, as we are using jmespath, we can extract only the data needed.
Still confused? Here’s a simple breakdown.
- We loop through the list of review entries found under reviews.edges.
- For each review, we use a jmespath query to pull only the relevant fields: rating, date, author, review text, and feedback scores.
- Ultimately, we get a clean list of dictionaries (dict). It holds one per review and contains only the fields we plan to export.
Step 6: Export the Reviews to a CSV File
Once the review data is cleaned and ready, the final step is to save it to a CSV file. Why is it necessary if the output is already displayed in the IDE? CSV makes the data structured and organized. Plus, you get to analyze, share, or feed into another tool without any issues.
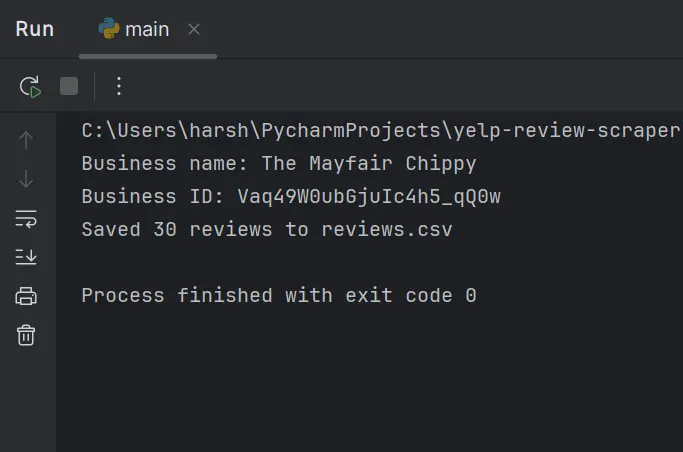
We begin by retrieving the business ID and name from the Yelp URL. Printing this info helps confirm that we’re scraping the right target.
Next, we initialize a review list and start collecting batches of reviews until we hit our target count (30). Each new batch is fetched via GraphQL and passed through our parser. If a batch comes back empty, we assume there are no more reviews to fetch and stop early.
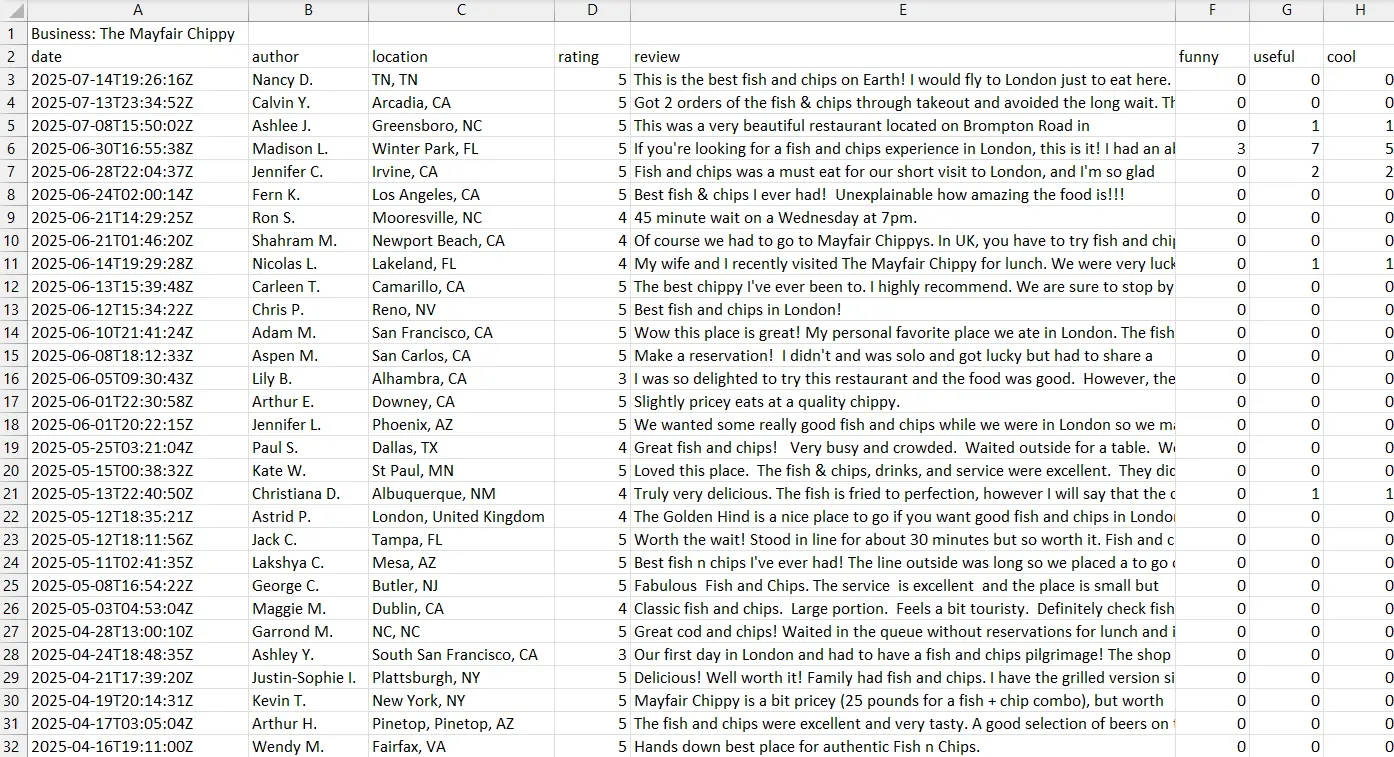
Here, we define the exact columns we want in our CSV. These match the parsed review data from earlier.
The script opens a new CSV file. To avoid confusion, the business name is listed in the first cell. Next, it adds the column headers and then writes each review as a row. We use UTF-8 encoding to handle special characters.
This is the final block that makes the function executable. When you execute the script, it is responsible for running the scraper.
Excited to try the Yelp Review Scraper? Here is the link to the complete code on GitHub Gist.
OUTPUT :
Bypassing Yelp’s Anti-Scraping Defenses
Curious about how Yelp’s anti-scraping systems work? To demonstrate, we ran a small test in which we attempted to scrape reviews from 10 restaurants once. We did this by simply pasting their URLs into Notepad, feeding them into a basic loop, and sending each request with the same header.
The result? Most requests failed. In many cases, the yelp-biz-id couldn’t even be located.
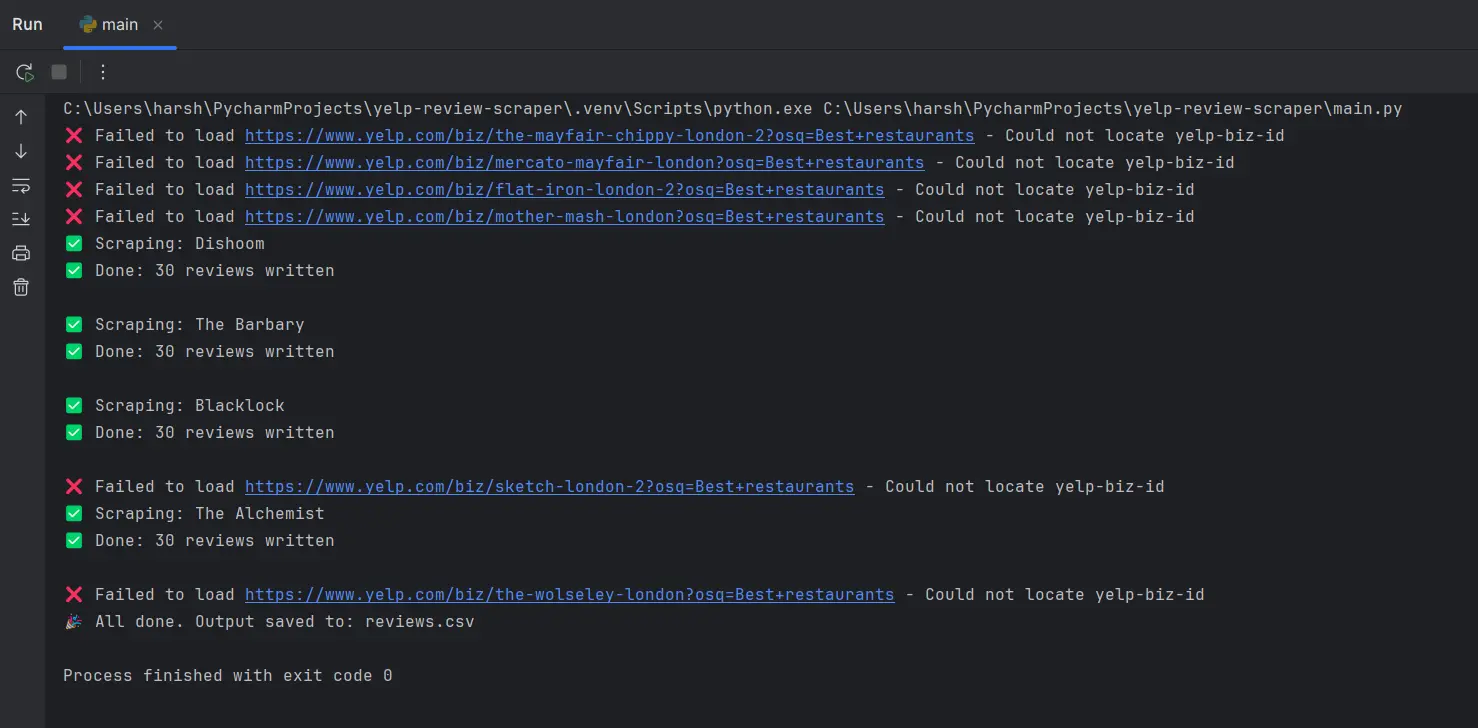
So what’s the way around the blocks? Here are our suggestions:
Header Randomization
HTTP headers like User-Agent, Accept, or Referer tell Yelp what kind of device or browser is making the request. If you send the same headers every time (like we did in the earlier test), the pattern gets detected quickly.
Hence, we recommend randomizing headers across requests. Just changing the string alone can help avoid detection in many cases. While handy and quick, headers are prone to detection and are ideal for small scraping tasks only.
Use Headless Browsers
A headless browser (browser without a user interface) is often used for scraping, especially when JavaScript rendering or full-page behavior is required.
If Yelp starts serving blank pages or hiding review content behind script-based loaders, you need to replicate user interaction. In such a scenario, using tools like Selenium or Puppeteer (popular headless browser drivers) is the ideal solution.
Use Rotating Residential Proxies
Proxies help disguise your IP address and avoid detection. They do this by spreading requests across different exit points. While they are different proxies, we suggest using residential proxies to scrape Yelp as they route traffic through real consumer devices, making it harder to flag.
Why use proxy rotation with residential proxies? Sending repeated requests from the same IP still gets you blocked. A good rotating residential proxy setup mimics organic user behavior while keeping your sessions alive across multiple targets.
Want to try it out? If you're just getting started with rotating residential proxies, grab our free 1 GB residential bandwidth trial to test things out before scaling.
Web Scraping APIs
If you find scraping complex and don’t want to write pages of code, you can try web scraping APIs. They offer a plug-and-play way to fetch structured data without getting into technical challenges.
They manage the anti-bot logic for you and return clean results. What’s the catch? They often have request limits or pricing tiers. But if configured properly, they can take your scraping efforts much further.
Best Practices for Scraping Yelp
Yelp doesn’t want you to scrape their site. Their Terms of Service explicitly prohibit the use of bots, spiders, or automated tools to access or extract data unless specifically allowed.
Also, their robots.txt blocks most dynamic paths like /biz/, /user_details/, and /search, fully disallows generic bots, and outright bans AI crawlers like GPTBot and Google-Extended.
If you still want to proceed with scraping while being legal and ethical, here are a few points to consider:
- If you're scraping Yelp for academic or research use, check out the Yelp Open Dataset. You can use it to access millions of reviews, photos, and business details in ready-to-use JSON format without scraping.
- Always prefer scraping public pages. We suggest avoiding sections of Yelp that require login, personalization, or user authentication. It’s the fastest way to violate platform rules and get flagged instantly.
- Regardless of the approach, use rotating residential or ISP proxies. They reduce your fingerprint and help you avoid common blocks like CAPTCHAs or blank pages. The best part? They work across almost every tool and work as an extra layer of defense.
- Add random delays between requests to mimic human behavior. Avoid sending too many requests per second or accessing the same domain from a single IP in bursts
- Yelp changes its HTML structure too often. Hence, prefer using labels, ARIA attributes, or relative XPath/CSS paths to keep your scraper stable over time
- Don't assume every request will succeed. We suggest you maintain logs to track errors, status codes, and missing fields. This way, you can adapt and act quickly when your scraper breaks.
Even with the right tools and practices in place, scraping too aggressively can result in IP bans or even legal notices. Always Respect Yelp’s rate limits and scrape only what you need.