How to Scrape Images from the Web

Working with images is crucial when gathering large sets of images, whether for machine learning, market analysis, content creation, or anything else. For this, you wouldn’t find a better source than the web, but if you have been doing it manually, it would take forever.
If you have been doing the same and are looking for an efficient way, web image scraping is one of the best ways. However, based on our analysis, this approach involves multiple challenges, including ethical and legal considerations.
This guide will help you get started with web image scraping and includes different methods for it, along with best practices for efficient and responsible web image scraping.
Methods for Scraping Images
According to the analysis aggregated by Ping Proxies, there are multiple ways to perform web scraping. However, not every method is the right fit, as the complexity of the website, the volume of images, technical skill, and other factors come into play.
Hence, different methods are included, ranging from beginner-friendly to advanced. Choose the one that best fits your web image scraping needs.
No-coding Image Scraper
If you have just started with web image scraping and aren’t proficient with coding, no-coding image scraper tools are the way to go. All you need to do is download the tool of your choice, add the URL, create a workflow, gather the image URLs, and download images.
While tools like Octoparse are ideal choices and they can speed up the setup and execution of scraping tasks without the hassle of coding, it often falls short when it comes to highly complex image scraping tasks with custom requirements.
Also, you might encounter limitations where the most crucial features are hidden behind a payment gateway, requiring a subscription.
CSS Selectors
CSS Selectors lay the foundation for web scraping by locating specific elements on a webpage with precision. It is based on HTML and lets you identify image tags and their attributes with ease.

If you’re scraping web images from a static page, CSS Selectors are the best choice, all you need is a good understanding of HTML. You can define patterns to target images based on class names, IDs, or hierarchical relationships in the HTML structure.
CSS Selectors can be used with Python through the BeautifulSoup libraries, making them the simplest and most lightweight solution. However, the catch is they are unsuitable for complex scenarios, and based on our analysis, any changes in the HTML can break the image scraping process.
XPath
XPath is yet another method for locating elements on the webpage. It is preferred by many for its flexibility to identify classes or IDs that are hard to find. In the case of web image scraping, it brings in the advantage of more precise targeting of image tags.
Unlike CSS Selectors, XPath allows you to navigate through the entire HTML document using a path-like structure. Combined with its conditional expressions, that filter elements based on specific attributes or text content, images hidden in deeply nested or complex structures can be scraped.

The drawback of XPath is similar to CSS selectors as it best works with static pages. According to the analysis aggregated by Ping Proxies, you can get over the limitation by using it with Selenium or Puppeteer and scraping dynamic pages. The catch of these added advantages is that learning and maintaining XPath expressions can be a hassle.
Automating with Selenium
If you’re looking for a more advanced and refined web image scraping method, Selenium can be your best pick. It is one of the most preferred choices for web image scraping due to its automation capabilities. You can use it with dynamic websites and replicate human interactions, such as clicking, scrolling, or navigating between pages to extract images efficiently.

Unlike the restrictions found in automation tools, Selenium makes automation flexible for everyone with its support for different Python, Java, C#, Ruby, Kotlin, and JavaScript. Plus, its compatibility with various browsers and integrations with proxies or external tools is an added advantage.
Automating with Selenium does come with a few concerns. If you’re using it with small web image scraping projects, look out for its excess resource consumption. Also, Selenium isn’t beginner-friendly and involves learning.
Want to automate with Puppeteer instead of Selenium, but aren’t sure which one to choose. Check our detailed Puppeteer Vs Selenium comparison to get started.
Online Tools to Download Images from URL List
If you find the above approaches too technical and want something straightforward without any complexity of learning and coding, you can use online tools to scrape web images. Based on our implemented research, the below tools are often recommended for web image scraping. Here’s a quick look at what makes each tool appealing and their potential drawbacks.
Image Cyborg
Image Cyborg is known for its simplicity. All you need to do is provide the URL and quickly scan the page for all images, presenting them for easy download. Upon creating an account, you get to use it for free for seven days.
However, this simplicity comes with limitations. While it works with a few dynamic websites, those with strict restrictions cannot be scraped. Regardless, it remains a go-to option for quick, small-scale scraping tasks.

extract.pics
Like Image Cyborg, extract.pics is free and allows you to input a URL and download images from the target webpage, but it has hour and daily limits. Based on our testing and analysis, it performed better with dynamic pages, but it struggles with the increase in restrictions.
It stands out by allowing you to use the tools without the need to create an account. Plus, it is more intuitive, and you get the added flexibility with the filters to download required images instead of all.

Both Image Cyborg and extract.pics are promising online web image scraping tools. They are particularly useful for non-technical users and smaller projects. According to the analysis aggregated by Ping Proxies, with more demanding needs, they often fall short, requiring you to purchase a subscription to use their full image scraping potential.
However, even that doesn't get you close to using the right automation tools like Selenium or Puppeteer if you set them right by using the proper configurations, browser automation techniques, and proxies to bypass even the most advanced challenges.
Scrape Images with Python
Python is a user-friendly and versatile programming language with its vast ecosystem of libraries and frameworks, making it ideal for scraping images from the web. May it be small or large-scale web image projects that involve static or dynamic pages, Python’s adaptability got you covered as you customize the scraping scripts to meet your needs.
Here are the most common methods for Scraping Images with Python:
- Using Requests and BeautifulSoup
- Automating with Selenium
- Using Scrapy for large-scale scraping
- Utilizing Playwright for JavaScript-heavy sites
- Parsing URLs with Regular Expressions
- Handling advanced challenges with Pyppeteer
With an idea of different web scraping image methods, if you want to get started without relying on online tools or methods that don't involve coding, the best approach is to start with Using Requests and BeautifulSoup.
To get you started with web image scraping, here is a small project performed on a static page.
Install the prerequisites
To get started with web image scraping using Python, you need to set up a proper environment. Here’s how to do it:
Step 1: First, download and install Python. Visit Python’s official download page, select the version compatible with your operating system, and proceed with the installation. It’s always recommended to use the latest stable version to avoid compatibility issues or deprecated features.

Step 2: If you’re using the Windows installer, check the box labeled “Add python.exe to PATH” during the installation. This step is crucial, as it allows you to use Python commands directly in your terminal without specifying the full path to the executable.

Step 3: Once Python is installed, you’ll need a Python Integrated Development Environment (IDE). While there are several options like Visual Studio Code, Spyder, and Jupyter Notebook, for this demonstration, PyCharm Community Edition is preferred as it is a free and user-friendly IDE perfect for learning and practicing web image scraping.

Step 4: After installing PyCharm, create a new project by selecting the "Pure Python" option. Set your project name and make sure the "Create a welcome script" box is checked. Once the project is created, open the main.py file and clear any existing content.

Step 5: With the project created, open the terminal within PyCharm by pressing Alt + F12 or clicking the terminal icon at the bottom left corner. Install the necessary libraries (Requests and BeautifulSoup) for web image scraping using the following command:

Import Required Libraries
With your PyCharm IDE set up and the necessary libraries installed, the next step is to import them into your project. These libraries are necessary for performing web image scraping and handling the data effectively.
In your main.py file, you’ll need the following imports:
- requests: This library is essential for fetching web pages. It enables you to send HTTP requests to the target website and retrieve the HTML content.
- BeautifulSoup: Part of the beautifulsoup4 package, this tool helps extract specific elements and data from the HTML, such as image URLs.
- csv: This module allows you to save the extracted data in a structured format, making it easy to access and analyze.
- os: A built-in Python module that helps manage the filesystem, such as creating directories for storing the scraped images.

Inspect your target
With the libraries imported, select your target website to get started. For demonstration, Books To Scrape is considered to scrape the images of book covers. Our goal is to pinpoint where the book cover data resides in the HTML and how to access it.
Step 1: Load the website on the browser and, right-click on any book cover image and select Inspect to open the Developer Tools.

Step 2: Hover the cursor over the book cover image in the Developer Tools, and you’ll notice it highlights a <img> tag. The src attribute within this tag contains the URL of the image.

Step 3: If you observe carefully, you’ll see that these <img> tags are nested within <div class="image_container">. It remains the same for all book cover images.

Step 4: Next, check the src attribute associated with the image. It is a complete URL with the relative path (/media/cache/) and the base URL (https://books.toscrape.com/) merged.

Step 5: As our target website has multiple pages, it’s important to handle pagination for complete web image scraping. In this scenario, the "Next" button at the bottom of the page uses a <li class="next"> element to navigate to the next page.
Each page follows the same layout, so once you identify the structure for one page, the same approach applies to the rest.
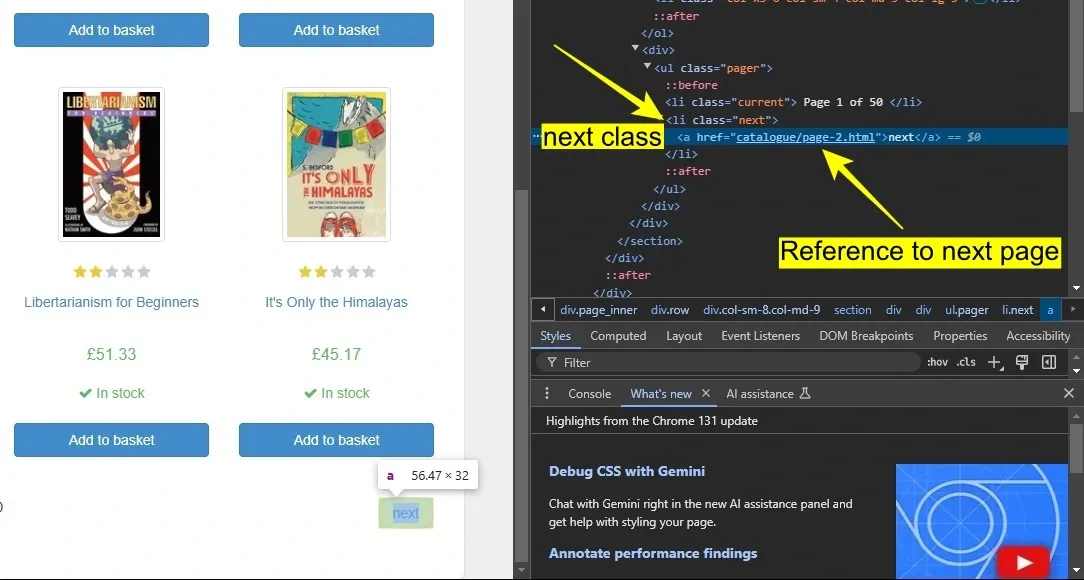
Define Base and Page URLs
Defining the BASE_URL and PAGE_URL variables helps navigate and extract data from the target website. These play a key role as they provide the structure needed to access pages and construct complete image URLs.

- BASE_URL: It is used to construct absolute URLs from relative paths found in HTML (it converts paths like media/cache/some-image.jpg into full URLs).
- PAGE_URL: It lets the script access pages sequentially. This is done with the help of ‘{}’, which serves as a placeholder for the changing page numbers.
Extract image URLs with the Beautiful Soup library
The fetch_image_urls() function navigates through all pages of the target site and extracts image URLs. It makes sure all image URLs are captured without the manual intervention of assigning each page for image scraping.

- Dynamic Pagination: The while loop checks all pages until an invalid page is encountered. The PAGE_URL.format(page_number) dynamically updates the URL with the current page number.
- Parse the HTML: The HTML page content is passed to BeautifulSoup to analyze using BeautifulSoup(response.text, "html.parser"). Once done it converts it into a structured format, making it easier to extract specific elements.
- Error Handling: The if response.status_code != 200: condition prevents unnecessary requests once all pages are covered.
- Image Extraction: The soup.find_all("img") finds all <img> elements in the HTML. The BASE_URL + img["src"] concatenates the base URL with the relative image path (src), to capture the full image URL.
- Return Value: The function collects all image URLs into a list and returns it for further processing.
Save the URLs to a CSV file
Once the image URLs are fetched, the save_to_csv() function saves the extracted URLs into a structured format, a CSV file, may it be for future reference or reuse.

- File Creation: The open("image_urls.csv", "w", newline="", encoding="utf-8") creates a new CSV file in write mode with UTF-8 encoding to handle special characters in URLs.
- Header Row: writer.writerow(["Image URL"]) adds a header row to the CSV for readability.
- Saving URLs: The for url in image_urls loop iterates through the list of image URLs and writes each one as a new row in the file.
Scrape images
The download_images() function downloads the images using the saved URLs. It creates a a new dedicated directory - “book_images”. Also, each image is named uniquely to avoid name overlapping which can halt the image scraping process.

- Directory Creation: The os.makedirs("book_images", exist_ok=True) creates a folder named book_images to store the images. The exist_ok=True ensures the script doesn't raise an error if the folder already exists.
- Downloading Images: The requests.get(url) fetches the image data from each URL in the list, and the file.write(image_response.content) writes the binary content of the image into a file.
- Unique Naming: The f"book_images/book_{index + 1}.jpg" makes sure each image gets a unique, sequential name like book_1.jpg, book_2.jpg, and so on.
Run All Functions
The script is executed from the if __name__ == "__main__": block. It puts all three functions in sequence and carries the image scraping process by fetching the URLs, saving them in CSV, and using it to download the images.

Finally, the web image image script is ready. Click the Run button or press Shift + F10 to execute the script. If you get the script right, you will find a CSV file with all the image URLs and a dedicated folder with all book cover images, both created in the project directory.


Complete source code
Want to test our Python web image scraping script? Here is the entire script put together.
Want to scrape more? Check out our other Python web scraping project to dive deeper into web scraping!
Ethical and Legal Considerations
Based on our implemented research, scraping images from websites can be a grey area. You must take the target website’s terms of service, local laws, and the intended use of the images into consideration and proceed with the image scraping.
- Respect Website Terms of Service: Always check the website’s terms of service before you get started with scraping. As most websites prohibit scraping, your IP gets banned or gets you into legal issues.
- Copyright and Ownership: Downloading and using them without permission can lead to legal consequences. Always prefer the public domains that are licensed for reuse. Proceed with the image scraping only when you have permission.
- Data Privacy: Avoid scraping personal data or images of individuals without consent. To prevent potential legal trouble, learn more about web scraping, pay attention to privacy regulations like GDPR or CCPA, and scrape accordingly.
- Limit the Scraping Load: Excessive scraping can overload a website's server. Be respectful by limiting the frequency of your requests, so you don’t disrupt the site’s functionality.
- Fair Use and Ethical Use: Even if an image is legally scraped, make sure it is used ethically. Reusing images without proper attribution or for commercial gain isn’t ethical.
Challenges and Best Practices
According to the analysis aggregated by Ping Proxies, web image scraping comes with several challenges. However, you can get over them by following the best practices. Here are the key challenges you may face and best practices to overcome them.
- Respecting Robots.txt: Before you begin with the image scraping process, always check the site’s robots.txt file to see if scraping is allowed. Doing this clears you from potential violations of the website’s policies and helps you avoid legal issues.
- Handling Dynamic Content: Many websites load images dynamically using JavaScript, making it hard to scrape with simple requests. To get over it, use tools like Selenium or Puppeteer, which can automate and interact with JavaScript and load images as they appear on the page.
- Dealing with Captchas and Blocks: Websites may block or restrict scraping through captchas or IP blocking. These setbacks can significantly impact your image scraping process, but with rotating proxies and proper automation tools, you can delay between requests to reduce the risk of detection.
- Maintaining Data Quality: Not all images will be properly formatted or relevant. Before saving or processing them, it's important to check the image URLs and make sure they meet the required quality standards.
- Optimizing Performance: Scraping large numbers of images can be slow and resource-heavy. To optimize your scraping process, use techniques like multi-threading or multi-processing and efficient data storage methods.
Conclusion
Online tools and no-coding solutions are ideal for beginners, offering ease and speed for small projects. However, they often come with limitations and subscription fees as your needs grow.
As discussed, there are various methods to scrape images from the web. While you might struggle with learning and generating scripts, you gain greater flexibility and control with automation frameworks.
Remember the challenges involved, and make sure you're scraping responsibly. Ping Proxies offers proxies that are legally and ethically sourced, these help you avoid blocks and ensure compliance, making your web image scraping process more reliable and efficient.