Data Parsing: What is it and how does it work?
Data parsing is the process of analyzing, interpreting, and extracting valuable information from an input data. It is a core step for enabling communication between software systems, as the communication mainly relies on data exchange between them.
It plays an essential role in a wide range of applications like document processing, web scraping, and API communication.
In this article, we’ll cover how data parsing works, what are some of the most common data parsing techniques, the role of data parsers, and the common challenges that appear with data parsing.
How Data Parsing Works
Data parsing requires that we first have a pre-defined standard format for the data. This format has its own rules for structuring the data and its contents. Much like a dictionary that includes the definitions and rules or a language. These rules are then implemented into a software component called a parser.
To start the parsing process, we provide some input data to this software. It then reads this data and starts analyzing it against the pre-defined standard rules for the data
format. If the data correctly adheres to these rules, the parser can successfully interpret its contents and enables us to extract specific information from the data or convert it to a different format if we need.
Common Stages in Data Parsing
The data parsing process can go through different steps depending on the parsing type and technique. But there are some steps that are considered common for most data parsers. These include the following:
Lexical Analysis
This is sometimes also called tokenization. It is the process of breaking down the input data into the smallest individual meaningful parts. Let’s say that we have a specific data format that defines objects as key-value pairs included within parentheses.
If we provide an input data like this ( name: John ) to a parser for this data, the tokenization process can break it down into four parts with the starting parentheses ( , the key name: , the value John, and the ending parentheses ).
The parser can then check that each of these parts actually has a meaning in the data format definition. If for example we provided curly braces instead of the parentheses, the parser can give an error in this stage like an unknown token, as the curly braces character is not defined as part of the language.
Syntax Analysis
After the parser checks in the lexical analysis that each component provided in the data is part of the data format definition, the next step is called the syntax analysis, which is to ensure that these components are arranged in a correct structure that also adheres to the data format standard.
Let’s say that the data was provided like this ( ) name: John, now each part of the data is still a valid token according to the data format, however, they don’t have the correct order of including the key-value pair within the parentheses. So although this input data can pass the lexical analysis, it will throw an error as part of the syntax analysis.
Output Generation
After the input data is analyzed against the data format definition, it can then be converted into or generate another structure that’s more usable for an application.
Data Parsing Techniques
There are many types of data formats and different techniques to parse each data type. Let’s cover some of the most common types and techniques that are used in a lot of modern applications.
String Parsing
String parsing is one of the most basic and fundamental parsing techniques. It involves breaking down a string of characters into smaller chunks or sub-strings that we can then process or extract information from. As we mentioned, we have to first define the rules for how we want the input data to look like, and how we want to break it down into smaller parts.
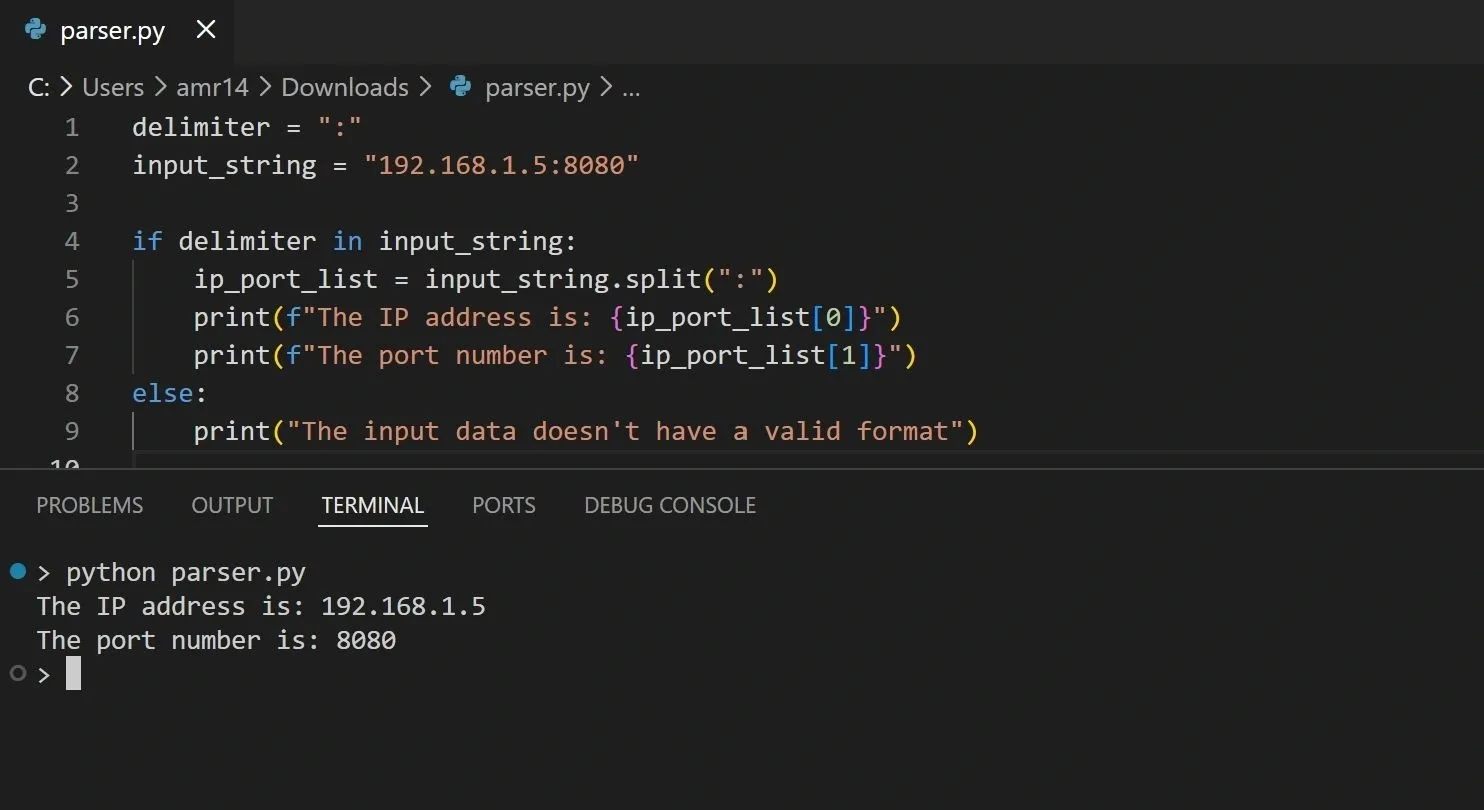
Let’s create a simple example in Python that parses an input string that contains an IP address and a port number. The input string must contain a colon character (:) that separates the IP address and the port:
Now, if we run this code, we should get the IP address and port separately:
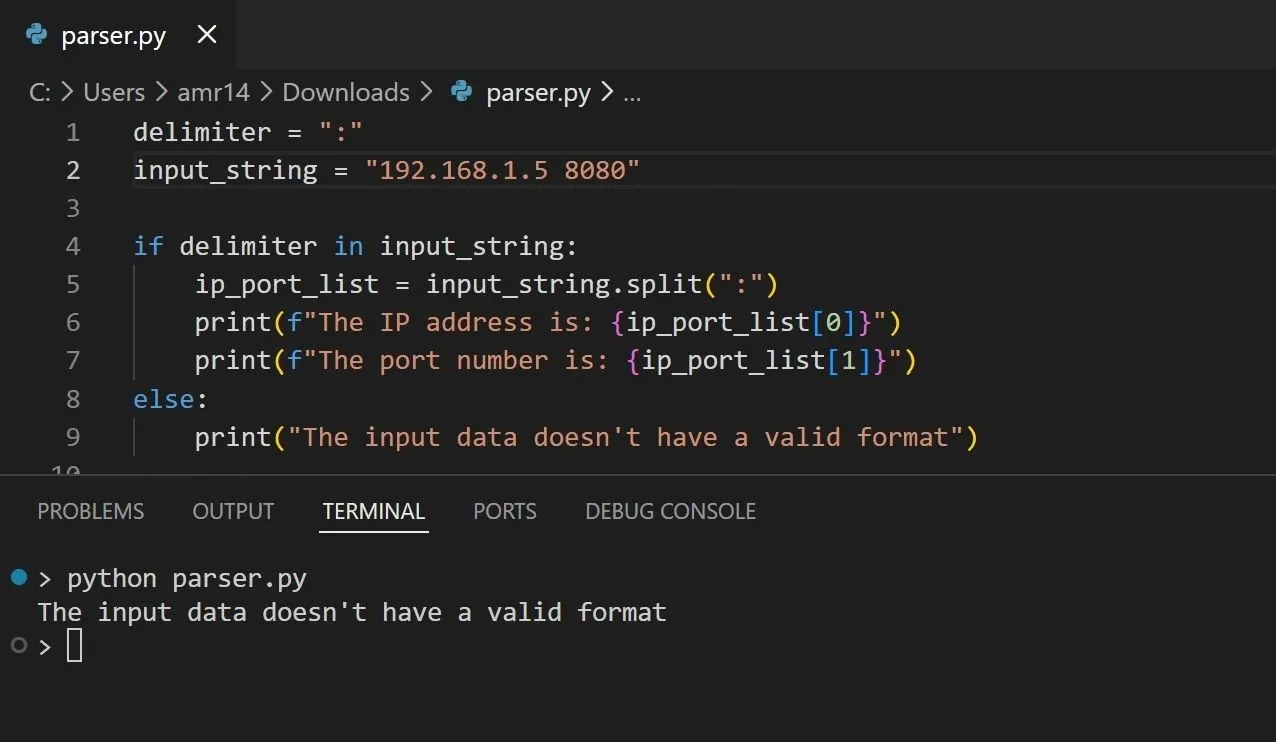
If we provide an input string without a colon, the code falls through to the else branch and prints an invalid-format message.
Regular Expression (REGEX) Parsing
Regular expressions define a pattern that consists of a specific sequence of characters. They can be used as a parsing technique to extract pieces of information that follow this character pattern from a large input data.
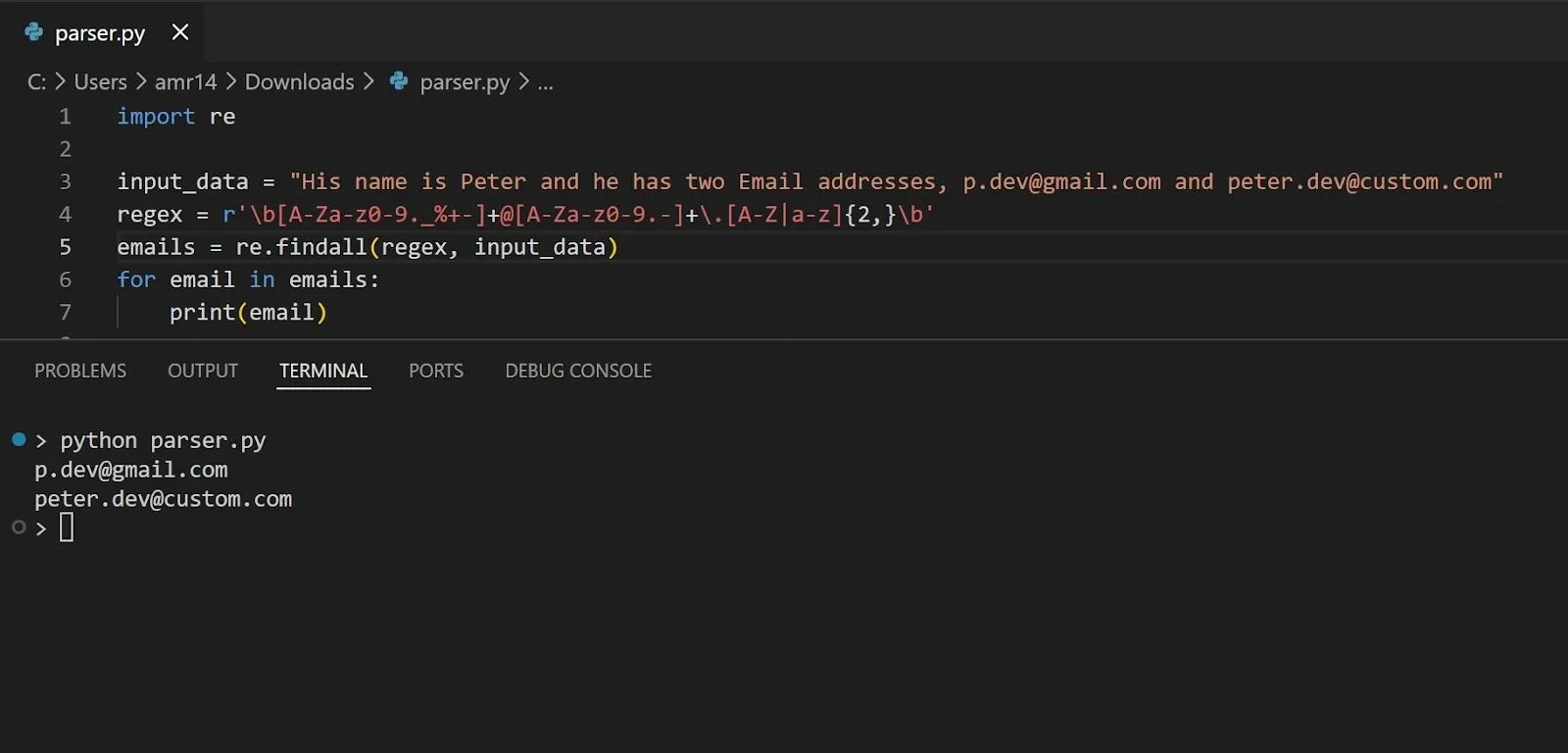
Regular expressions are implemented in different tools and scripting languages. Let’s use the Python regular expression syntax to show an example of parsing a text to extract valid Email addresses from it:
In the above code, the regex variable is what defines the pattern or sequence of characters that we want to match against for extracting valid Email formats that adhere to this pattern. If we run the above code, we should get the Email addresses provided in the input text:
Using regular expressions is one of the most common text data parsing techniques. You just need to understand the regular expression syntax, and then you can define whatever pattern-matching rules you want. However, using regular expressions in production needs a keen eye for detail, as its complexity can lead to unnoticed mistakes that can turn into major outages.
XML Parsing
XML is a markup language that is used to store and transport data between applications. It represents the data in a format that’s readable for both humans and machines. It has its own standard syntax rules that the data should be structured with.
XML parsing is used to extract information from XML documents. It breaks down the XML data into smaller individual elements that we can then specify how to process the information from. XML parsers are typically implemented in programming languages as ready-to-use libraries that we can import and utilize for extracting the information from XML data.
For example, we can parse XML data in Python as follows:
In the above code, the xml_data variable is a string that contains input data which represents a list of courses in XML format. We then use the xml.etree.ElementTree Python module to parse this data and extract some information about each course and display it.
JSON Parsing
JSON is also another text-based data structuring format that is used to store and transport data between applications. It is lightweight and has its own syntax with wide support and compatibility for almost all major programming languages.
Similar to XML, JSON parsing involves breaking down the JSON data into smaller elements and attributes to extract information from it. Parsing JSON can also convert the data into programming language objects with their attributes.
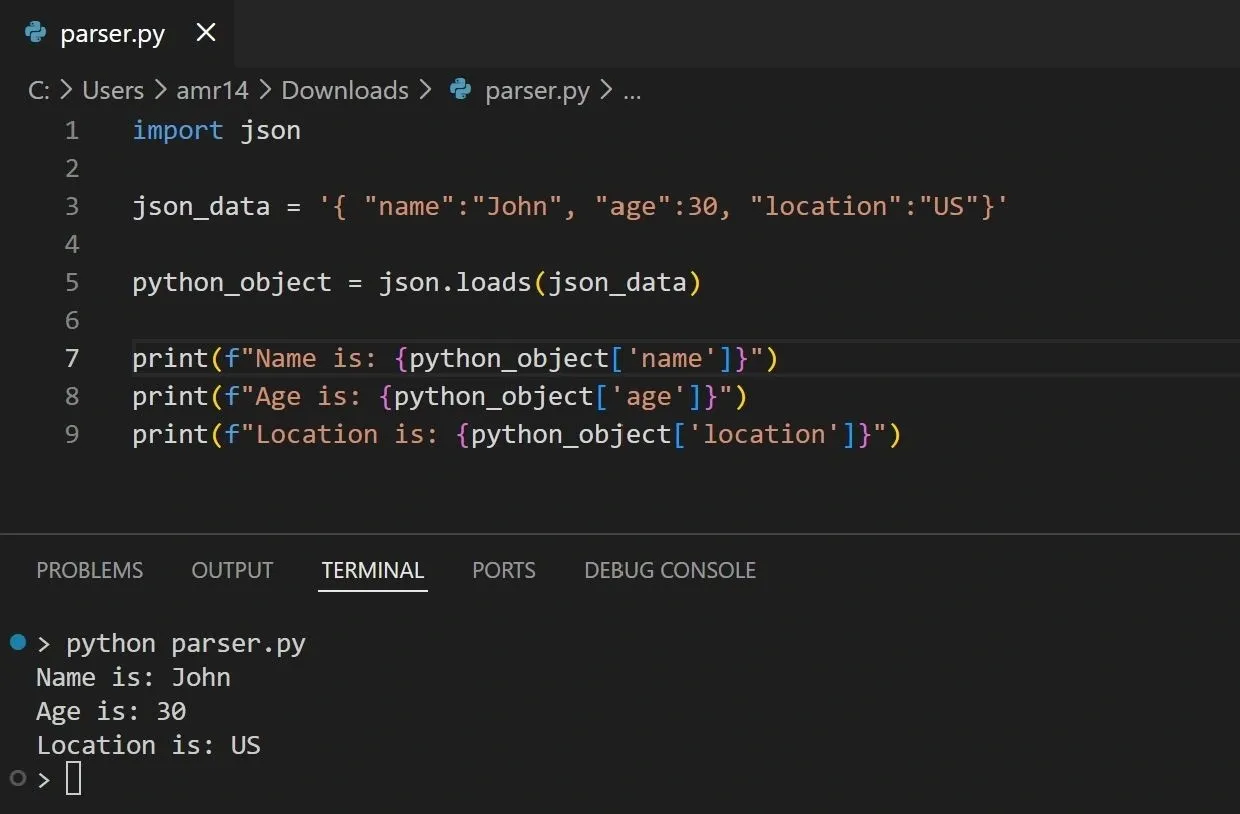
Again let’s see an example of parsing JSON with Python:
In the above code, we use the Python json module to parse the input data that is provided in the json_data variable. This parsing converts the JSON string into Python data structures (usually a dictionary and/or lists). You then extract values using dictionary keys like python_object['name'].
HTML Parsing
HTML is one of the earliest markup languages that was originally developed to represent web page contents. It also has its own syntax for representing data elements that make up the structure of a web page. HTML can be parsed to extract information from it which is a common practice in web scraping, and it’s also parsed into a DOM representation inside web browsers as part of displaying a web page contents.
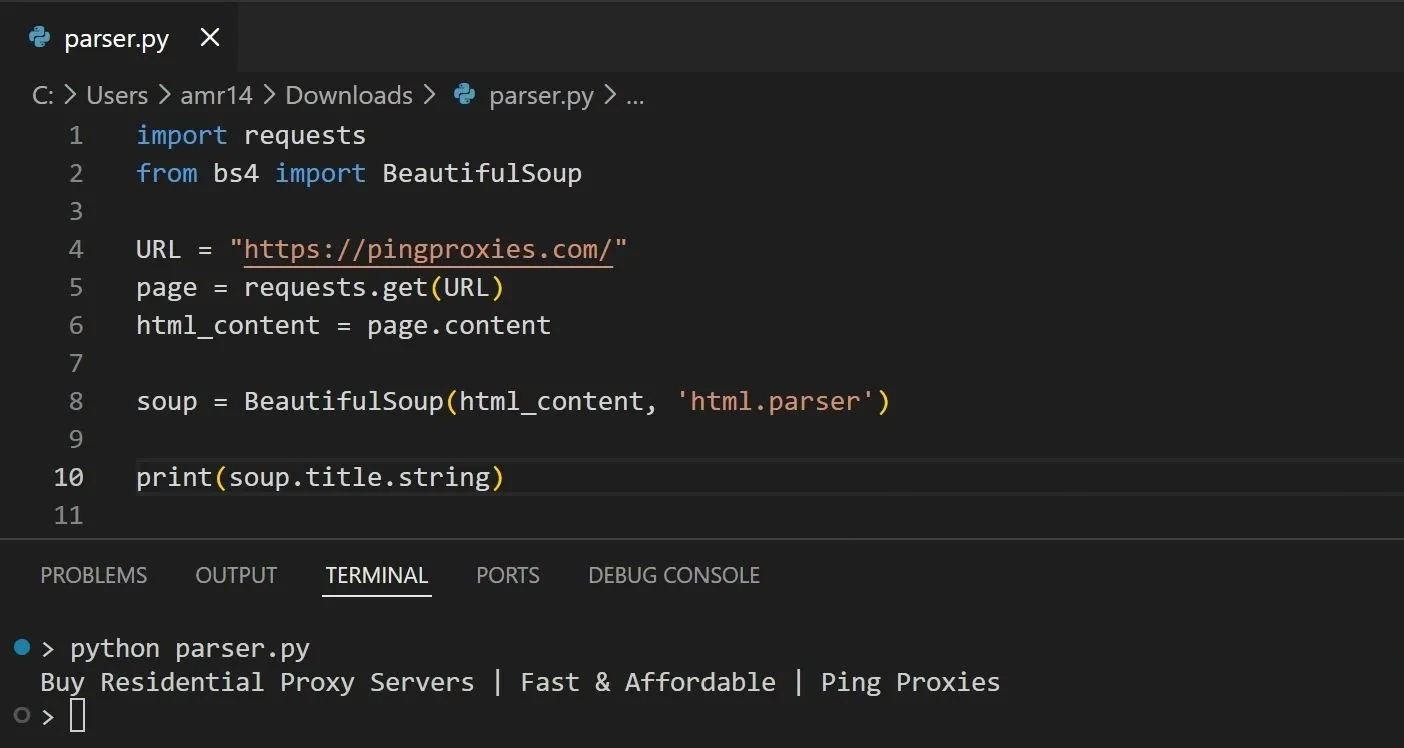
To see an example of parsing HTML, we’ll use Python’s BeautifulSoup library combined with the requests library. This is a very common and popular usage for such scenarios where the requests library is used to fetch the HTML of a page from its URL, while the BeautifulSoup library is used to parse and extract information from this HTML content:
The above code will display the contents of the <title> tag in the provided page:
The Role of Parsers in Data Parsing
As we mentioned before, parsers are software components that can understand and interpret the data format and enable us to extract specific information from this data. For example, in the previous JSON parsing scenario the Python json module is the parser that was able to read the input data string and convert it into a corresponding Python object with its attributes.
Parsers are the essential component in processing and transforming data for a wide range of applications. It is the component that actually implements the different stages (Lexical analysis, Syntax analysis, etc) for handling the input data. Parsers are used in applications like web page display inside browsers, data extraction in web scraping, database SQL query processing, and much more.
We can use readily available parsers like some of the libraries that we’ve seen in previous examples, or we can build our own parser if we have specific needs like handling a different non-standard data format. The complexity of building a parser depends on the details of the data format and structure that it should process.
Common Data Parsing Challenges
Because data parsing involves multiple steps to ensure the quality and accuracy of the extracted information, there can be multiple challenges that arise along each step of the process. Let’s explore some of the most common challenges that appear when parsing data.
Inconsistent Data Formats
When the input data is received from different sources, a common challenge is that the data can be provided in multiple formats. Using a single-format parser in such scenarios can lead to errors or missing data for the formats that the parser doesn’t support.
To overcome such challenge, we can use flexible data parsers that support different formats and can convert from one format to another. It’s also essential to understand from the beginning of the design what the input data format will look like, so we can use the best option for the parser.
Missing or Incomplete Data
Another challenge in data parsing is when the data has some missing (empty or null values). A parser that’s not designed to handle missing data can incorrectly interpret the data or throw an error.
A solution to this problem can be to use a parser that’s able to handle missing data by providing default values, adding placeholders, skipping incomplete data blocks, or gracefully handling the error. It’s also important to double-check the resultant parsed data and verify that it’s complete and correct.
Parsing Performance
Data parsing can incur a lot of performance overhead on applications, especially when the size of the data gets larger. To overcome this problem, it’s important to consider the type of parser being used and ensure it’s the optimal choice for the needed type of data.
For example, the parser shouldn’t include unnecessary parsing steps that might not benefit the application for the provided input data. We can also use parsers that are implemented in lower-level languages, which will have a faster execution time.
Wrapping Up
Data parsing is an essential process for reading and extracting information from input data. It enables different applications and systems to communicate with each other by exchanging data in a standard format that they agree on, so they can both interpret and process it.
Data parsing is typically implemented using a software component called a parser, which has the logic to understand the structure of the data, extract specific fields from it, or convert it into another format. Parsers can have different types depending on the data parsing technique that’s required.
To implement an efficient parsing process, it’s important to consider the type of data and parser needed, plan for handling common data parsing challenges, and decide upon what output is required from the parsing that satisfies the needed business value.